



Uniform blog/Faster and more scalable personalization
Faster and more scalable personalization

Faster and more scalable personalization
It’s hard enough for a brand with a high-traffic web site to ensure fast site performance during traffic spikes. It’s even harder when the site includes personalization. As the number of visitors increases, so do page load times, along with the likelihood that visitors will bounce.
Limitations of traditional DXP architectures
The impact on site performance is mainly due to the architecture used by most “enterprise-grade” Digital Experience Platforms (DXP). These systems often require the DXP to act as the site “origin”. In web architecture, the origin is the name given to the system responsible for delivering content to the visitor.
In order for the DXP to deliver a personalized experience to a visitor, the DXP must execute logic in order to determine the appropriate content for the visitor and to package that content into HTML that the visitor’s browser can display. Individual page components are personalized in this way, so pages with multiple page components have more logic that needs to run.
In order for this to work at scale, the DXP must be able to handle a large number of visits. This often requires scaling up (increasing the power of a specific instance) or scaling out (increasing the number of instances). If visitors are distributed around the world, instances of the DXP must run in data centers around the world, as the visitor’s physical distance from the DXP has a large impact on performance.
Even when the DXP is scaled in this way, there is still a requirement that each DXP instance is able to handle requests quickly. If an instance can’t do this, visitors will either have to wait a long time for the site to load or, in the worst case, be unable to access the site at all. This helps explain why many large brands have tried turning on personalization, only to turn it off when they realized personalization resulted in poor performance and site outages.
Improving performance with a CDN
The fastest sites do not depend on their DXP to act as the origin. They use a CDN (content delivery network) as the origin. A CDN is a globally distributed, high-performance delivery network that is able to scale automatically to handle changes in traffic load. The CDN sits in front of the DXP, only making calls back to the DXP when absolutely necessary.
In the past, this presented a challenge for sites with personalization and other kinds of dynamic content. If this dynamic content is generated by the DXP, it was necessary for every request to be handled by the DXP. The benefit of the CDN was limited to handling static files like images.
Today, brands have several options for decoupling personalization functionality. Marketing technologist and business users can continue to use their DXP to enable and control personalization, but the execution of that personalization can be separated, or decoupled, from its configuration. Personalization can be executed on the CDN, also called “the edge”.
(In case you’re curious about why the CDN is called “the edge”, it’s because of the way the CDN is a globally distributed network. The CDN is just as fast for someone in San Francisco as it is for someone in Berlin. That’s because the person in San Francisco is served by the part of the CDN located geographically close to San Francisco. That is the “edge” of the CDN. Similarly, the person in Berlin is served by the edge of the CDN closest to Berlin.)
Personalization on the edge
From a marketing technologist or business user’s perspective, nothing changes. The way personalization is enabled remains the same. But moving the execution of personalization from the DXP to a CDN means the way that personalization works changes. Understanding these changes is important in order to design a site that can be as fast as possible. Getting the fastest possible performance means realizing the difference between things you can do and things you should do.
Just like with DXP-based personalization, CDN-based personalization depends on data being available when the personalization logic runs. When thinking about CDN-based personalization, it is helpful to organize the data that drives this logic into three categories:


These categories are not only differentiated by the kinds of data they represent. They are also differentiated by something called “potential reach”. Potential reach is a relative measure of how many visitors can be targetted, or reached when personalization is based on that kind of data. Large (or high) reach means a large number of visitors can be reached. Small (or low) reach means a small number of visitors can be reached.
Reach also reflects the quality of the data insights that are gathered as a result of the personalization. Personalizing using data with high reach will, by definition, apply to a larger population. It’s not as precise as personalizing using data with low reach which, while it applies to fewer visitors, provides a more relevant experience for those visitors.
There are advantages and disadvantages to personalizing with low, medium and high reach data. In most cases, you will get the best results when you personalize using data from all three categories.
Category 1: Data available at the edge when the visitor arrives
When a visitor views a page, certain data is passed along with the request. This is the data included in the HTTP request. It includes the following:
- Device information — Browser type, browser version, operating system, etc.
- URL — Hostname, query string parameters, etc. Inbound marketing campaign ids are typically included in the URL.
- Cookies — Information collected as the visitor has viewed the site, either during the current session or a previous one.
- Language
- Visitor IP address
- Date/time
In addition, the CDN may provide data based on the HTTP request. Some common examples include:
- Location — This can be determined from the visitor’s IP address.
- Device capabilities — This can be determined using a variety of device details, including the visitor’s browser type and operating system.
- Third-party data — Insights from DMP, ABM, etc. can be matched using the visitor’s IP address or a third-party cookie.
This kind of data is the easiest to personalize with because it is available automatically and without any additional configuration or custom development.
Category 2: Data based on real-time behavior
As a visitor navigates a site, the visitor’s session behavior can be collected. Examples of this kind of data include:
- Specific pages viewed
- Number of pages viewed
- Goals/events triggered — For example, adding a product to a shopping cart or signing up for a newsletter.
- Scoring based on behavioral profiles — For example, interest in a particular product category or lead scoring.
The component that collects this behavior is called a tracker. When a DXP is the origin, it can run a tracker itself. This means all of the visitor activity is collected on the DXP, which is convenient because it requires little-to-no addition configuration.
That convenience comes at the price of performance and scalability. Activity for each visitor must be stored in the DXP, usually in memory, at least temporarily. Sites with a lot of visitors end up having to store a lot of data, which reduces the performance of each instance and increases the need to either scale up or out.
But trackers can run on the client, too. Google Analytics tracker is an example of this. If a client-side tracker is used, that significantly reduces the amount of work the DXP needs to do when it handles visitor requests. A tracker can store visitor behavior on the browser, which means the visitor remains in control of all of his or her data.
If visitor behavior data is captured in a client-side tracker, that information can be made available to the CDN using options available in category 1. For example, the tracker may store the number of pages viewed in a cookie. Doing this means the visitor behavior is available to the CDN.
Category 3: Data based on visitor information
The final category of data describes an individual visitor. This data usually comes from a customer database or the DXP. Common examples include:
- Gender
- Age
- Contact relation (e.g. customer, partner, etc.)
- Orders
- Products/services purchased
- Opportunities
While this data might be stored on the client (and, therefore, an example of category 2 data), more often the data must be retrieved from the system of record. This requires an API call to the system of record.
The amount of time it takes for this API call to complete depends on the health, location and scale of the system of record. If visitors cannot view your site until this data is available, that can create performance problems for your site. As a result, this type of personalization should be implemented in a way that does not prevent the visitor from interacting with your site. Techniques such as “lazy loading”, positioning this type of personalization below the fold, or including it on second page-views offer solutions.
How to minimize the need for category 3 personalization
Getting the best possible personalization performance and minimizing the cost of DXP infrastructure usually involves reducing the use of personalization that requires additional API calls. You also get the benefit of easier compliance with privacy legislation like GDPR and CPA.
To be fair, personalizing on the data that uniquely identifies a visitor is compelling. This article is not trying to portray this type of personalization as something that is incompatible with good site performance. But it is worth considering how important this type of personalization is, especially since studies show that site performance has a much greater impact on customer engagement than personalization.
In cases where personalizing on this kind of data is required, you want to minimize the number of API calls needed to collect the data used for personalization. Consider personalization based on the visitor’s contact relation (whether the visitor is a customer or a partner).
In this example, the data is stored in the DXP. Upon visitor login, this value can be stored in a cookie. This way the data can be handled like category 1 data. Or, if you are sending an email campaign to all partners, you can use a parameter in the URL to classify the visitor is a partner. URL parameters are category 1 data. And you can store the value in a cookie for future personalization needs.
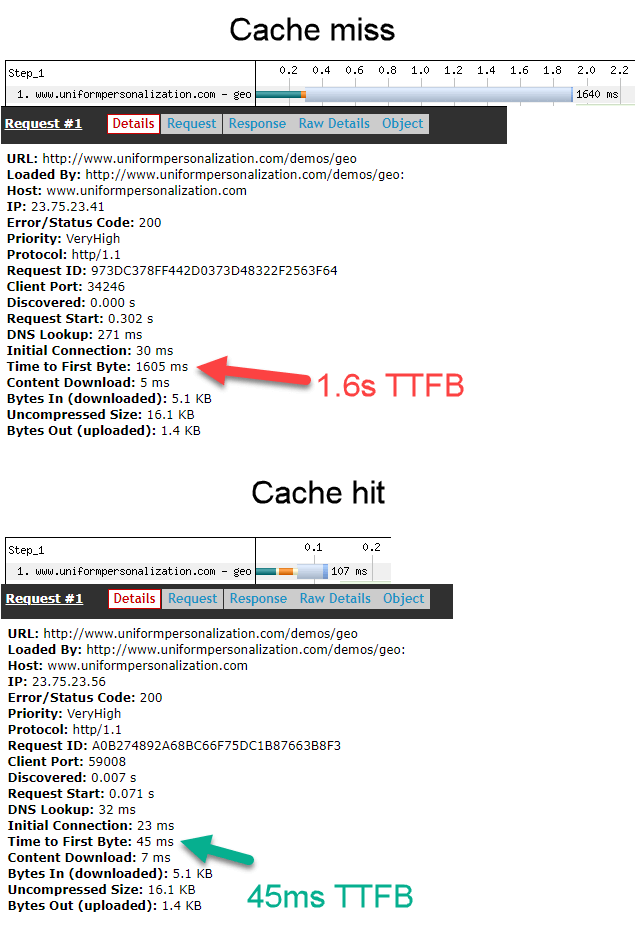
Real performance benefits of CDN-based personalization
The image below highlights the difference in performance between DXP-based personalization and CDN-based personalization. In this example, the personalization is based on the visitor’s country. The CDN used was Akamai.
TTFB (time to first byte) is the amount of time it takes before the visitor’s browser start receiving any data from the origin. Sub-second TTFB is what engineers aim for. In this simple personalization example, TTFB for DXP-based personalization is 1.6s, while TTFB for CDN-based personalization is 45ms. CDN-based personalization is more than 35x faster.

Using the same example, the page load time for DXP-based personalization is 3.2s compared with 0.69s for CDN-based personalization.


Fast, scalable personalization with the systems you have with Uniform
Edge-based personalization is possible with your existing DXP. This approach gives you the best of all possible worlds:
- All personalization is enabled through the DXP
— The processes used by marketing technologists and business users do not change at all. They continue to use the tools offered by the DXP to configure and control personalization. - Visitor activity data is stored where it’s needed
— Data collected can still be stored in the DXP if desired, but the data can also be stored in other systems, such as Google Analytics. This also creates the opportunity to report on personalization using tools like Google Data Studio and Microsoft Power BI. - Infrastructure costs are optimized
— Optimize your infrastructure cost by moving more logic (also known as “compute”) to a CDN, which is more cost-efficient than scaling the DXP infrastructure. - Custom integrations are eliminated
— Third-party data sources don’t have to be integrated with the DXP. All data that is needed is either already available or is provided to the edge from the client.
Uniform enables edge-based personalization with the platforms and products you choose. For example, with Sitecore Experience Platform, you can deploy edge-based personalization on a variety of CDNs, including Akamai, AWS, Azure CDN, Cloudflare and Netlify.
Do check out our personalization strategy workbook and get started on intent-based personalization today.


